提纲:
- 机器学习为什么可能?
1. 引入计算橙球概率问题
2. 通过用Hoeffding's inequality解决上面的问题,并得出PAC的概念,证明采样数据学习到的h的错误率可以和全局一致是PAC的
3. 将得到的理论应用到机器学习,证明实际机器是可以学习
机器学习的大多数情况下是让机器通过现有的训练集(D)的学习以获得预测未知数据的能力,即选择一个最佳的h做为学习结果,那么这种预测是可能的么?为什么在采样数据上得到的h可以认为适用于全局,也就是说其泛化性的本质是什么?
课程首先引入一个情景:
如果有一个装有很多(数量很大以至于无法通过数数解决)橙色球和绿色球的罐子,我们能不能推断橙色球的比例?

很明显的思路是利用统计中抽样的方法,既然我们无法穷尽数遍所有罐子中的球,不如随机取出几个球,算出其中两种颜色球的比例去近似得到我们要的答案,

这样真的可以么?我们都知道小概率事件也会发生,假如罐子里面大部分都是橙色球,而我们恰巧取出的都是绿色,这样我们就判断错了,那么到底通过抽样得出的比例能够说明什么呢?似乎两者不能直接划等号。
由此,课程中引入了一个非常重要的概念,PAC,要理解这个,先得理解一个超级重要的不等式:Hoeffding’s inequality
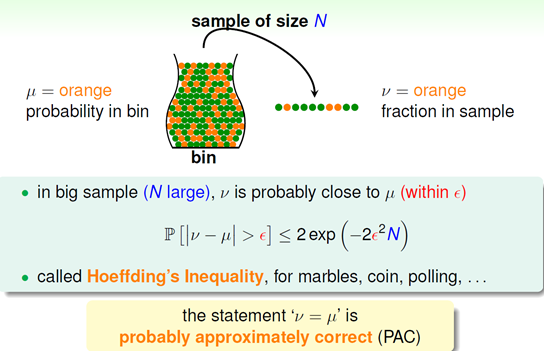

这个不等书说明了对于未知的那个概率,我们的抽样概率可以根它足够接近只要抽样的样本够大或者容忍的限制变松,这个和我们的直觉是相符的。式子最后给出了PAC的概念,即概率上几乎正确。所以,我们通过采用算出的橙球的概率和全局橙球的概率相等是PAC的。
这些和机器学习有什么关系?其实前文中提到的例子可以和机器学习问题一一对应:
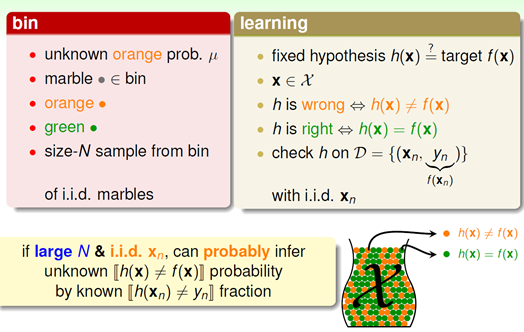
映射中最关键的点是讲抽样中橙球的概率理解为样本数据集D上h(x)错误的概率,以此推算出在所有数据上h(x)错误的概率,这也是机器学习能够工作的本质,即我们为啥在采样数据上得到了一个假设,就可以推到全局呢?因为两者的错误率是PAC的,只要我们保证前者小,后者也就小了。
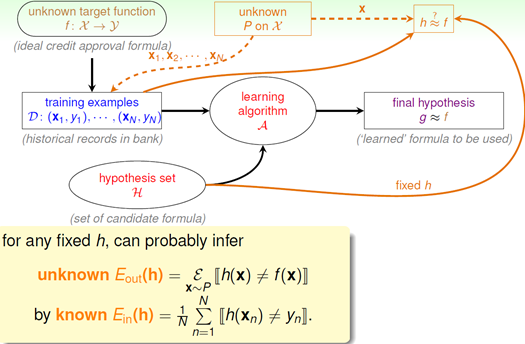

请注意,以上都是对某个特定的假设,其在全局的表现可以和其在DataSet的表现PAC,保证DataSet表现好,就能够推断其能泛化。可是我们往往有很多假设,我们实际上是从很多假设中挑一个表现最好(Ein最小)的作为最终的假设,那么这样挑的过程中,最小的Ein其泛化能力一定是最好么?肯定不是。


上面的例子很形象,每一个罐子都是一个假设集合,我们默认是挑表现最好的,也就是全绿色(错误率为0)的那个假设。但是当从众多假设选择时,得到全对的概率也在增加,就像丢硬币一样,当有个150个童鞋同时丢硬币5次,那么这些人中出现5面同时朝上的概率为99%,所以表现好的有可能是小概率事件发生(毕竟对于每个假设其泛化能力是PAC),其不一定就有好的泛化能力(Ein和Eout相同),我们称这次数据是坏数据(可以理解为选到了泛化能力差的假设),在坏数据上,Ein和Eout的表现是差别很大的,这就是那个小概率事件,Hoeffding’s inequality告诉我们,每个h在采样数据上Ein和Eout差别很大的概率很低(坏数据):

由于有这个bound,那么我们每次选取Ein最小的h就是合理的,因为如果M小N大,出现表现好的坏数据的假设几率降低了,我们选择表现后就有信心认为其有良好的泛化能力。

总结一下:
- M小,N足够大,可以使得假设具有良好的泛化能力;
- 如果同时,Ein很小,那么这个假设就是有效地。机器是可以学习的,学习到的就是这个表现最好的假设。
整体证明机器可以学习分了两个层面,首先对于单个假设,根据Hoeffding不等式,当N很大时,其泛化能力强是PAC的;而实际上机器学习是从众多假设中挑Ein最小的(通过测试集找)假设,这个的理论基础是当M不大,N大,选到泛化能力差的假设概率低(用到了单个假设的结论)。

